Stylistics Comparison of Human and AI Writing
Christopher Sean Harris, Evan Krikorian, Tim Tran, Aria Tiscareño, Prince Musimiki, and Katelyn Houston
Results
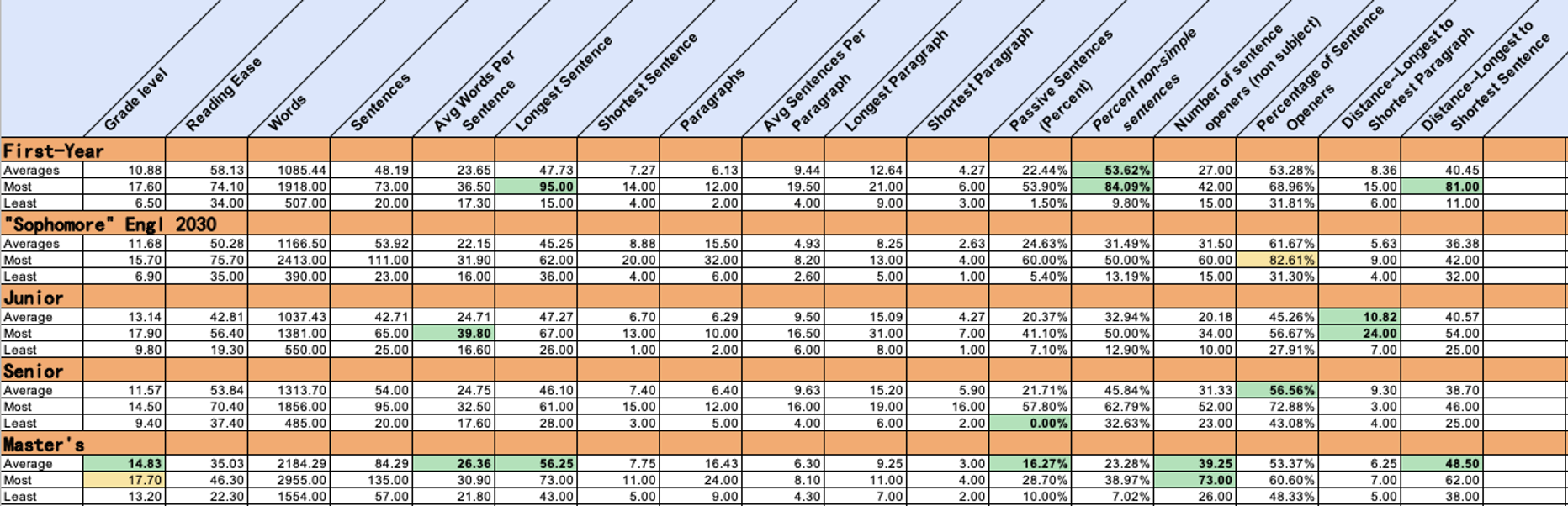
Generalized, the results from the style study are mixed, as both humans and machines scored garnered preferable results in a variety of categories; however, disambiguating humans into grade level revealed that the graduate students performed the best in the most categories even though their genre of critical introduction seemed to lend itself to short sentences and less-varied prose. Given that the data for large language models (LLMs) comes from human writers and humans train GAI, it would make sense that the writing samples are somewhat similar.
Student-Led Data Analysis
Human writing averaged a slightly lower Flesch-Kincaid grade level than AI writing. While the human writing samples averaged a 12.16 Flesch-Kincaid grade level, AI achieved a 2% higher average at a 12.43 Flesch-Kincaid grade level. ChatGPT averaged a 28% higher Flesch-Kincaid grade level in its writing samples than Google Bard, however, averaging a 14.00 Flesch-Kincaid grade level and a 10.90 Flesch-Kincaid grade level, respectively. On average, humans wrote at a higher Flesch-Kincaid level than Google Bard but a lower Flesch-Kincaid grade level than ChatGPT4.

Human writing averages a higher reading ease than AI writing. Humans wrote at a 25% higher reading ease than AI, averaging 49.43 and 39.51, respectively (30–50 is the college range). ChatGPT4 wrote at a 36% and 20% lower reading ease than both human writing and Google Bard, respectively, however, with an average score of 31.52. Google Bard wrote at an average reading ease of 47.31. Humans came closer to writing “plain English” than AI, though plain English represents 8th-9th grade level writing.
AI writes paragraphs with fewer sentences than humans, yet it is more complex according to the Reading Ease score. Our human writing samples contained an average of 8.20 sentences per paragraph, compared to an average of just 3.54, 3.44, and 3.49 sentences per paragraph for, Google Bard, ChatGPT4, and All AI writing samples combined, respectively. The AI writing samples were also typically uniform in paragraph length, largely ranging from 2–4 sentences per paragraph. However, on the occasion that AI did stray, the paragraphs spun out of control and made little sense.
Even though human writing and both types of AI writing samples (Google Bard and GPT4) contained single-sentence paragraphs, many Bard writing samples contained both paragraphs comprised of single sentences and numbers in the double-digits. Essay 5.3.4000.Bard has a one-sentence paragraph and a 14-sentence paragraph while essay 7.3.2000.Bard contains a one-sentence paragraph and a 14-sentence paragraph. While engaging writing indeed depends on variation, such a drastic difference in length for brief texts with few paragraphs borders on irrationality and outright ineffectualness according to our student researchers.
On average, the shortest paragraph of a human writing sample is twice as long as an AI paragraph in number of sentences. A representative one-sentence paragraph from a human writer came in an I-Search essay as the writer refocused on their research question.
That's when I asked myself the question again: “What is better: when the teachers grade students, when grading of assignments is computerized, or is it better when the grading system is abandoned altogether?” (44.2.3000)
A one-sentence AI paragraph of the same level is a concluding paragraph. The language, the polysyllabic words, offer evidence about grade level and readability, but closer examination confers Katelyn’s claim that AI writing often unraveled as it became longer. Just what does “lifelong multilingualism and intercultural competence” mean? The essay reported on Nina Spad's "Language Learning in Early Childhood," not on the erasure of language and culture.
understanding and applying these principles, educators can create effective and nurturing learning environments that support the diverse needs of young language learners, setting the foundation for lifelong multilingualism and intercultural competence. (44.1.3000.GPT)
Humans are more likely to write passive sentences than AI. An average of 21.54% of all sentences in human writing samples were passive sentences, compared to just 13.86% of all sentences in AI writing samples. Google Bard wrote nearly 2 percent (1.83%) more passive sentences than GPT4, however, with 14.76% and 12.93% of all sentences being passive sentences, respectively. The algorithm directing AI writing, or its training, most likely indicate a preference for sentences with the subject to the left of the verb.
By the numbers, humans trump artificial intelligence in average sentence length, managing to claim the lead for shortest average sentence (at 7.51 words) and longest average sentence (at 47.57 words). Humans even excel at the average rate of non-simple sentences (at 39.31%) and at sentence openers (at 53.25%). Humans also beat both Bard and GPT4 in its shortest and longest distances between the paragraph and sentence lengths.
All of these “successes” in each average make sense, too, when you realize AI produces a mainly-consistent length for each output it creates, while our human data involved a wide variety of students that had their own individual (and oftentimes, verbose) ways of composition. As such, though humans exceed in a quantitative metric, the qualitative efforts of their writing is an important, yet unfortunately missing, comparison that needs not be forgotten.
Perhaps one challenge in the study comes in assessing first-year writing students. Since those students are often learning how to write with clarity and concision, their wildly varying statistical data resemble Gorgias’s young charioteer trying to control both a wild and tame horse at the same time.
While the 95-word sentence penned by a first-year student is sound, it stands out as a loose and wild sentence.
“It can be argued that she is the combination of three ground-breaking characters for Marvel comics: standing out being a person of color such as The Falcon who would later take on the mantle of Captain America, standing out being a woman with her own story instead of being simply a side character such as one of the most iconic female superheroes to get an issue of their own Captain Marvel, and standing out being a teenager who must balance their life at home with their life as a superhero such as The Amazing Spider-Man.” (1.6.1000)
By comparison, the second-longest sentence comes from a graduate student. This sentence is also sound, but it could be tamed.
“A student’s final grade will be a holistic grading composing of student’s attendance and class participation, in-class writing and quizzes, workshop feedback, submission of two poems, a 10-page minimum academic essay incorporating one’s theoretical understanding of mythological fiction genre and an explication of a myth fiction story, and a culminating final creative nonfiction story (built into a portfolio) incorporating all of the genres discussed in class.” (6.3.5000)
In the English department, perhaps text is all too often considered blocks of paragraphs filling a page. Perhaps students avoid subheadings and lists because they are strange and non-literary. The graduate student’s sentence would fare better as a numbered and itemized list which might facilitate parallel structures and logical ordering.
On the other hand, the first-year student could probably also benefit from a list, but their writing task is different, more complex. Rather than order assignments, the student is attempting to explain Kamala Kahn’s multifaceted representation. The student attempts to describe how Kahn draws her representation from features of three other characters as well as being a teenage, woman, primary character and person of color. In a revision, the student could take advantage of the power inherent in repeating “standing out.”
Finally, the longest AI sentence, written by Google Bard, is a summative paragraph at the end of an interview transcript, and it also is a list. (Yes, AI can spoof interviews.) The sentence has fine grammar but suffers from stylistic malaise. Richard Lanham’s paramedics need to resuscitate the sentence, perhaps by removing the first ten words.
It is important to note that the burdens of second language learning can vary depending on a number of factors, such as the student's age, their native language, the quality of the English language instruction they receive, and the level of support they have from their family and community. (55.2.4000.Bard)
Richard Lanham devised the Paramedic Method to help college writers write clearly and concisely, so it’s not fair to single out AI for wordiness after examining a 95-word sentence.
Google Bard is statistically better at emulating human writing than GPT4, according to Katelyn, as she states, I am not surprised that human and AI writing are statistically similar because AI writing software is very much the product of human writing: i.e., large language models (LLMs). However, speaking of wordiness, our statistics are not—and should not—be the only means of assessing a piece of writing's "quality," something I, a human, could easily discern when reading through the human writing and AI writing samples, as such statistics alone lack the context of a piece of writing’s content.
While gathering data, we noticed a significant qualitative difference in the content of AI writing and human writing. Human writing displayed a higher concentration of actual content, as evidenced by the middle paragraphs being longer in length than the introductory and concluding paragraphs. By contrast, we noticed that a significant portion of the AI writing samples were top- and bottom-heavy; in other words, AI writing demonstrated the tendency to write longer introductory and concluding paragraphs, a strong indication that AI writing lacks the substance of true, quality analysis backed by thinking.
Human writing arguably has much more to say with the same amount of words. If there is one area where AI writing possesses a genuine aptitude, however, it would be repetition. AI writing is skilled in the art of tautology; the software lacks variety in its vocabulary and phrasing.
Tim notes that our collected data, from student samples or generated ourselves with two prominent AI writing platforms, is that collegiate essays written by AI tend to be more consistent with elements such as paragraph length and words per sentence compared to students of all grade levels, who tended to have a wider range between longest to shortest sentences and paragraphs. In addition, the student essays we used as examples were collected final drafts from essay assignments, meaning that, while many of them probably received good grades, they all had at least one typo or syntactical error whereas essays generated by Google Bard and ChatGPT, by design, did not contain humanlike user errors or typos.







